Esta modelo relacional transformada al modelo de red sería la siguiente:
Esta modelo relacional transformada al modelo de red sería la siguiente:
2)En este ejemplo, los tipos de registros son: CURSO, REQUISITO, OFERTA, PROFESOR y ESTUDIANTE. CURSO es el tipo de segmento raiz:
 Esta modelo relacional transformada al modelo de red sería la siguiente:
Esta modelo relacional transformada al modelo de red sería la siguiente:
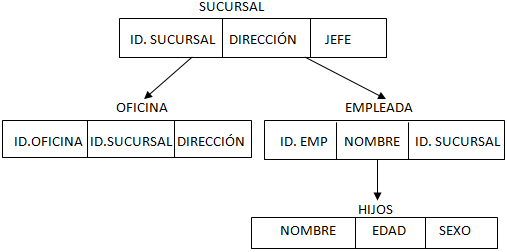
 A continuación, el modelo de datos jerárquico de la figura anterior:
A continuación, el modelo de datos jerárquico de la figura anterior: 2) En este ejemplo presentaremos la estructura del modelo de datos jerárquico de un departamento de estudios de una univeridad.
2) En este ejemplo presentaremos la estructura del modelo de datos jerárquico de un departamento de estudios de una univeridad.




SEGMENTO RAÍZ: El segmento raíz de una base de datos jerárquica es el padre que no tiene padre. La raíz siempre es única y ocupa el nivel superior del árbol.
La raiz en el ejemplo sería: "empresa".
Una OCURRENCIA de un segmento de una base de datos jerárquica es el conjunto de valores particulares que toman todos los campos que lo componen en un momento determinado.
Un REGISTRO de la base de datos es el conjunto formado por una ocurrencia del segmento raíz y todas las ocurrencias del resto de los segmentos de la base de datos que dependen jerárquicamente de dicha ocurrencia raíz.
La relación PADRE/HIJO en la que se apoyan las bases de datos jerárquicas, determina que el camino de acceso a los datos sea ÚNICO; este camino, denominado CAMINO SECUENCIA JERÁRQUICA, comienza siempre en una ocurrencia del segmento raíz y recorre la base de datos de arriba a abajo, de izquierda a derecha y por último de adelante a atrás.
El esquema es una estructura arborescente compuesta de nodos, que representan las entidades, enlazados por arcos, que representan las asociaciones o interrelaciones entre dichas entidades.
La estructura del modelo de datos jerárquico es un caso particular de la del modelo en red, con fuertes restricciones adicionales derivadas de que las asociaciones del modelo jerárquico deben formar un árbol ordenado, es decir, un árbol en el que el orden de los nodos es importante. Una estructura jerárquica, tiene las siguientes características:
- El árbol se organiza en un conjunto de niveles.
- El nodo raíz, el más alto de la jerarquía, se corresponde con el nivel 0.
- Los arcos representan las asociaciones jerárquicas entre dos entidades y no tienen nombre, ya que no es necesario porque entre dos conjuntos de datos sólo puede haber una interrelación.
- Mientras que un nodo de nivel superior (padre) puede tener un número ilimitado de nodos de nivel inferior(hijos), al nodo de nivel inferior sólo le puede corresponder un único nodo de nivel superior. en otras palabras, un progenitor o padre puede tener varios descendientes o hijos, pero un hijo sólo tiene un padre.
- Todo nodo, a excepción del nodo raíz, ha de tener obligatoriamente un padre.
- Se llaman hojas los nodos que no tienen descendientes.
- Se llama altura al número de niveles de la estructura jerárquica.
- Se denomina momento al número de nodos.
- El número de hojas del árbol se llama peso.
- Sólo están permitidas las interrelaciones 1:1 ó 1:N
- Cada nodo no terminal y sus descendientes forman un subárbol, de forma que un árbol es una estructura recursiva.
- El árbol se suele recorrer en preorden; es decir, raíz, subárbol izquierdo y subárbol derecho.
type alumno = record
nombre: string[30];
control: string[8];
materia: Materia; {Enlace a materia}
end;